Matt Kennedy and I have recently written a corrigendum to our paper “Essential normality, essential norms and hyperrigidity“. Here is a link to the corrigendum. Below I briefly explain the gap that this corrigendum fills.
A corrigendum is correction to an already published paper. It is clear why such a mechanism exists: we want the papers we read to represent true facts, so false claims, as well as invalid proofs or subtle gaps should be pointed out to the community. Now, many many papers (I don’t want to say “most”) have some kind of mistake in them, but not every mistake deserves a corrigendum – for example there are mistakes that the reader will easily spot and fix, or some where the reader may not spot the mistake, but the fix is simple enough.
There are no rules as to what kind of errors require a corrigendum. This depends, among other things, on the authors. Some mistakes are corrected by other papers. I believe that very quickly some sort of mechanism – say google scholar, or mathscinet – will be able to tell if the paper you are looking up is referenced by another paper pointing out a gap, so such a correction-in-another-paper may sometimes serve as legitimate replacement for a corrigendum, when the issue is a gap or minor mistake.
There is also a question of why publish a corrigendum at all, instead of updating the version of the paper on the arxiv (and this is exactly what the moderators of the arxiv told us at first when we tried to upload our corrigendum there. In the end we convinced them that the corrigendum can stand by itself). I think that once a paper is published, it could be confusing to have a version more advanced than the published version; it becomes very clumsy to cite papers like that.
The paper I am writing about (see this post to see what its about) had a very annoying gap: we justified a certain step by citing a particular proposition from a monograph. The annoying part is that the proposition we cite does not exactly deal with the situation we deal with in the paper, but our idea was that the same proof works in our situation. We did not want to spell out the details because we considered that to be very easy, and in any case it was not a new argument. Unfortunately, the same proof does work when working with homogeneous ideals (which was what first versions of the paper treated) but in fact it is not clear if they work for non-homogeneous ideals. The reason why this gap is so annoying, is that it leads the reader to waste time in a wild goose chase: first the reader goes and finds the monograph we cite, looks up the result (has to read also a few extra pages to see he understands the setting and notation in the monograph), realises this is is not the same situation, then tries to adapt the method but fails. A waste of time!
Another problem that we had in our paper is that one requires our ideals to be “sufficiently non-trivial”. If this were the only problem we would perhaps not bother writing a corrigendum just to introduce a non-triviality assumption, since any serious reader will see that we require this.
If I try to take a lesson from this, besides a general “be careful”, it is that it is dangerous to change the scope of the paper (for us – moving form homogeneous to non-homogeous ideals) in late stages of the preparation of the paper. Indeed we checked that all the arguments work for the non-homogneous case, but we missed the fact that an omitted argument did not work.
Our new corrigendum is detailed and explains the mathematical problem and its solutions well, anyone seriously interested in our paper should look at it. The bottom line is this as follows.
Our paper has two main results regarding quotients of the Drury-Arveson module by a polynomial ideal. The first is that the essential norm in the non selfadjoint algebra associated to a the quotient module, as well as the C*-envelope, are as the Arveson conjecture predicts (Section 3 in the paper) . The second is that essential normality is equivalent to hyperrigidity (Section 4 in the paper).
Under the assumption that all our ideals are sufficiently non-trivial (and some other standing assumptions stated in the paper), the situation is as follows.
The first result holds true as stated.
For the second result, we have that hyperrigidity implies essential normality (as we stated), but the implication “essential normality implies hyperrigidity” is obtained for homogeneous ideals only.
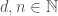 , there exists a constant
, there exists a constant 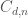 such that for every row contraction
such that for every row contraction 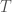 consisting of
consisting of  commuting
commuting 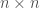 matrices and every polynomial
matrices and every polynomial 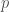 , the following inequality holds:
, the following inequality holds: .
. is the
is the 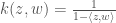 .
. to a subset of the unit ball (see Theorem 6 and its corollary in
to a subset of the unit ball (see Theorem 6 and its corollary in  . To the best of my knowledge, no other Hilbert function spaces with such a universal property have been studied.
. To the best of my knowledge, no other Hilbert function spaces with such a universal property have been studied. , of the form
, of the form .
.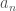 is a sequence of positive numbers). These are Hilbert function spaces on some half plane that have a kernel of the form
is a sequence of positive numbers). These are Hilbert function spaces on some half plane that have a kernel of the form  .
. the “generating function” of the space, and if we write
the “generating function” of the space, and if we write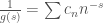 ,
,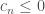 for all
for all  .
.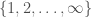 . For example,
. For example, 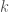 is given by
is given by ,
, is the
is the 